
在AI界各种传言数月后,OpenAI终于在π日(3月14日)发布了人们翘首以待的GPT-4。果然如所料,这是一款多模态超大模型。GPT-4 实现了以下几个方面的显著提升:
- 相较于之前的版本只接受文本输入,GPT-4也可以接受图像输入,已经具有较强大的识图辩解能力。
- GPT-4着重提升了机器的推力能力,对许多话题的回答准确性和相关性显著提高。在答题应试方面的能力已经超过90%以上的高中生和大部分的大学生。
- 文字输入限制提升至 2.5 万字,大大扩张了人机交流的密度和强度。
- 在非英语语言方面的能力有了显著的提高。
- 能够生成歌词、创意文本,实现风格变化。
- 在模型安全性上有重大的改进,如梦幻式的胡言乱语会减少,对响应敏感请求(例如,医疗建议和自我伤害等)的应对上也会更有分寸。
在GPT-4正式发布前,Bing(必应)搜索器其实已经整合了GPT-4的功能。在发布后,OpenAI也直接升级了ChatGPT。
GPT:面壁3年,破壁成学霸
提升机器的推理能力是本次迭代的重点所在。在3年前GPT-3发布的时候,其推理计算能力还只是小学低年级的水准。经过3年面壁,GPT-4的推理能力已经不可同日而语了。闲话少说,直接亮晒成绩单:
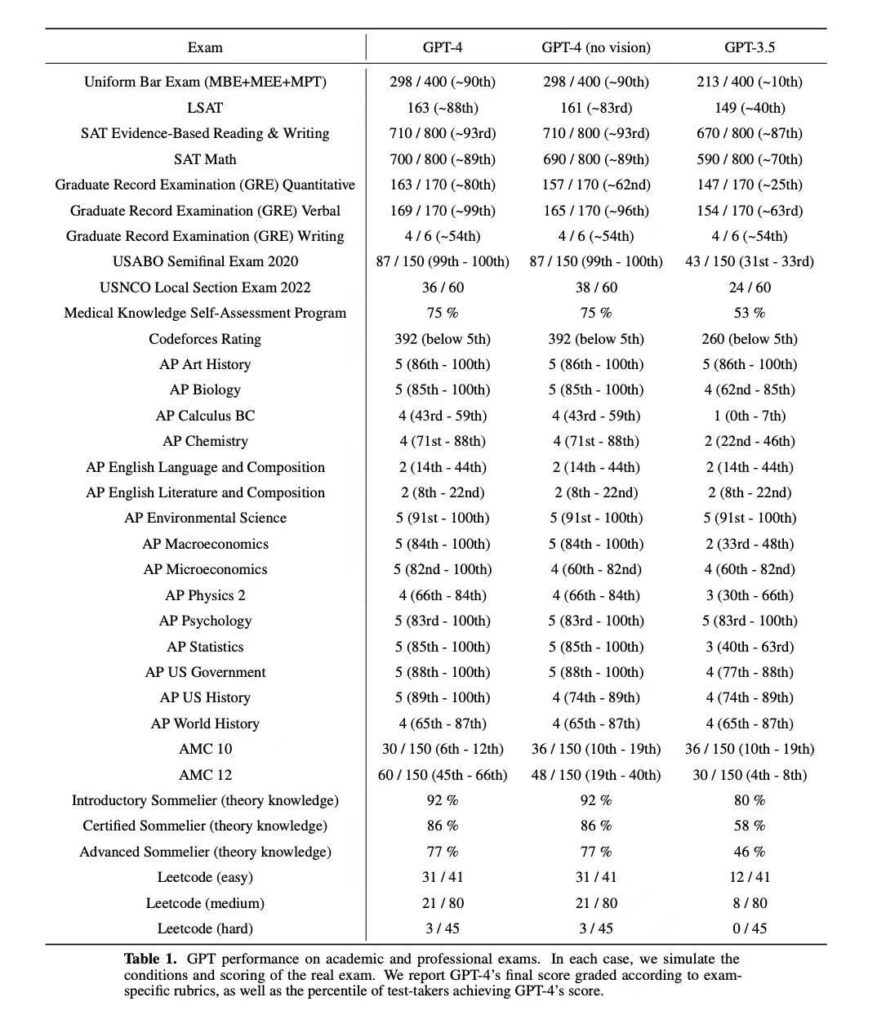
OpenAI特意指出,这些成绩的取得,重在能力的提升,并不是靠给GPT大量喂题后产生的效果。GPT-4就像是一个突然开悟的少年,秒杀众多的小镇做题家。
从具体科目成绩看,GPT-4还是有点偏科,在词汇,生物,化学等需要记忆大量具体知识点的科目上表现出众,而数理方面的能力还是弱一些。所以将来GPT这样的工具对文科学科的文献整理综述,对生物,化学,材料科学等的研究的价值会首先体现出来。
GPT:我也懂图梗
作为多模态模型,GPT-4除了可以接受文字输入,也可以接受图像输入。不仅能够辨识图像,还能解读一些内涵意蕴。这是之前的版本没有的能力。
输入这张图,问GPT-4有啥特异的地方,GPT-4回答说这烫衣服人的怎么给绑到出租车顶上了?

再输入这张图,问它这是什么梗?


GPT-4回答说,就这就想糊弄我?尽管堆得有点像世界地图上的五大洲,但这些终究是炸鸡块!
虽然已经有了接受图像输入的功能,但是OpenAI目前还不准备把这个功能开发给大众测试。估计这图像方面已经有了进展,但还是有一些技术问题要解决。图像和视频的信息占比人们日常的信息量很大,这是迈向AGI的必由之路。但是因为没有一些语法结构和语境的内在约束,图像视频信息处理所需要的参数量可能和文本类信息都不在同一个数量级上。现有的技术框架是否能够较好解决图像视频的问题,还有待观察。
看完Demo和技术报告后,总体感觉这次迭代是属于优化型迭代。可能OpenAI也会像Apple公司发布iPhone一样,奇数版本才是升级版迭代。




